Abstract
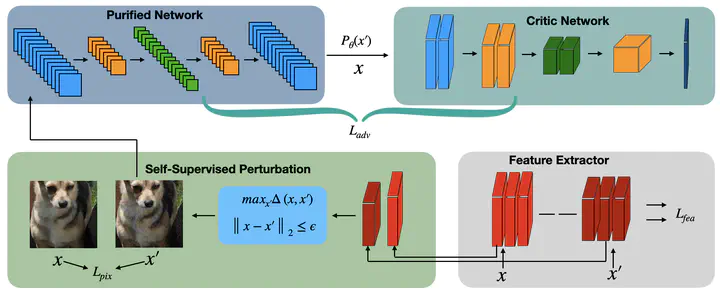
Deep learning based techniques are broadly used in a variety of applications such as image recognition, natural language processing, etc., which express leading performance than traditional methods. However, adversarial samples can cause severe problems for deep learning models, especially for vision-based deep neural networks. Adversarial training is a commonly adopted strategy to defend adversarial samples, but it lacks generalization capability due to the transferability of adversarial samples to work on cross-task predictions. In addition, the input processing method of deep learning pipeline can improve generalization capability for cross-task predictions, whereas processing newly generated adversarial samples is the major bottleneck that limits its performance. To deal with these issues, this paper proposes a purification mechanism that combines both adversarial training-based and input processing-based methods to defend the threats of adversarial samples. The proposed mechanism has a strong generalization capability for various vision-based deep learning tasks by leveraging the advantage of input processing-based methods and maintaining the defense efficiency of adversarial training-based methods. Comprehensive experiments are conducted on multiple datasets that demonstrate the superiority of the proposed approach against the state-of-the-art methods on defending adversarial samples.
Honghui Xu 许宏辉
Ph.D. Candidate
My research interests include machine learning, deep learning, and data privacy.